Tout le monde ou presque connaît le Page Rank alias PR pour les intimes. Le page rank est un des éléments qui permet de calculer la pertinence d’une page par rapport à une requête effectuée sur Google. Le page rank est souvent défini comme un indice de notoriété d’une page web, indice de notoriété qui d’ailleurs a ses limites : il génère naturellement un frein assez important à l’apparition de nouveaux entrants et par essence la notoriété n’étant pas forcément liée à la qualité (en l’occurence le contenu de la page) mais à sa visibilité, il peut favoriser des pages fortement hyperlinkées mais au contenu à faible valeur.
Toutefois comme précisé le PR n’est qu’un des éléments permettant de calculer la pertinence des pages sur une requête.
Pour approfondir la notion de page rank on peut rappeler l’équation fondatrice de cet indicateur qui est :
PR(B) = (1-d) + d x ( PR(A1) / N(A1) + … + PR(An) / N(An) )
équation dans laquelle PR signifie page rank , B est la page dont on veut connaître le PR, A1,…, An sont des pages comportant un lien vers la page b, et d est un indice strictement compris entre 0 et 1, N(Ai) étant le nombre de liens sur la page N.
On peut voir tout ça à l’adresse originale de diffusion de ce contenu sur :
http://www-db.stanford.edu/~backrub/google.html
Pour plus de clarté on pourra aussi consulter :
http://www.webmaster-hub.com/publication/article16.html
Cette notion était trés novatrice à l’époque. Elle positionnait le web comme une sphère de pages liées entre elles et criait haut et fort que si un webmaster prenait la peine de faire un lien vers un autre site cela voulait dire qu’il estimait son contenu. La page ciblée héritait aussi alors d’une partie de la notoriété du site pointant, notoriété répartie à parts égales entre tous les liens présents sur la page de départ.
Bien évidemment, cet algorithme de calcul du page rank a évolué au fil du temps et on pourra trouver des éléments plus récents d’étude sur son mode de calcul sur le document "Deeper Inside PageRank" par Amy N. Langville et Carl D. Meyer du 20 octobre 2004 et dont la traduction est disponible sur le site de l’Agence Ultra-fluide. (Non matheux s’abstenir) (qu’Olivier dévoilait il y a fort longtems.)
Mais le Page Rank n’est pas l’objet de ce billet. Ce qui m’amène à vous c’est une nouvel indicateur que Google met en place : le Trust Rank.
En effet vous avez peut être remarqué dernièrement sur Google apparaître des résultats en première position présentés de façon fort différente (avec plusieurs liens pour le même site par exemple.)
Ca ressemble à ca :
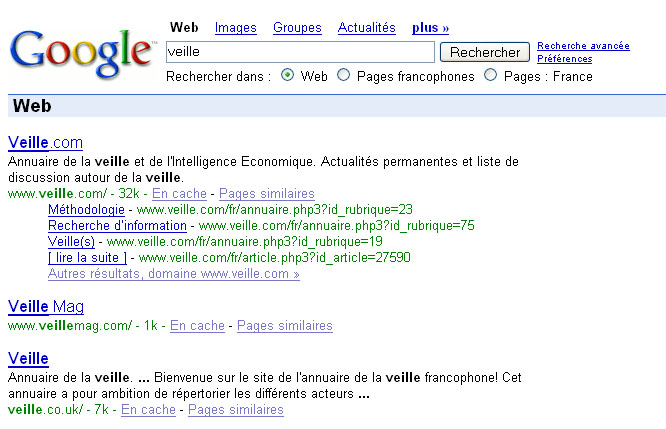
On parle du Trust Rank désormais depuis plus d’un an, mais ce n’est que ces dernièrs mois que l’on a commencé à voir apparaître de plus en plus fréquemment des résultats différents sur Google qui laissent penser que certains sites bénéficient du label "Google Trusts in you!" (marque non déposée) et sont ainsi récompensés par une visibilité accrue.
Le trust rank (compris en tre 0 et 1, 1 étant un site de confiance et 0 un site spamdexeur), dont l’article fondateur "Combating webspam with TrustRank" de 2004 est accessible ici, est un algorithme semi-automatique commeOlivier (Duffez cette fois-ci) nous l’explique succinctement. Ne nous voilons pas la face, les annuaires sont globalement un échec, à part DMOZ qui survit, la plupart sont morts car trop lourds à entretenir, trop coûteux. Pourtant le Trust Rank reprend ce principe. Google sélectionnerait des sites manuellement (en petit nombre), et les sites vers lesquels ils pointent hériteraient de la confiance accordée par Google à ce site.
Toutefois pour l’instant aucune confirmation officielle de Google sur ce fameux Trust Rank, mais de nombreux indices convergents qui laissent penser que la bonne vielle validation humaine reste quand même sacrément efficace y compris du haut de Mountain View.
NB : PageRank et TrustRank sont des marques déposées par Google
Tags : trust rank, page rank, trustrank, pagerank, pertinence, google



